之前写过一篇文章:Java分布式缓存实现方案之Spring Cache,分享给大家。
一. 场景
小白:哥,今天我做分布式缓存时,看到公司用了Spring Cache,这个技术你能给我讲讲吗?
我:没问题!来,听我给你说分布式缓存怎么搞。
二. 缓存介绍
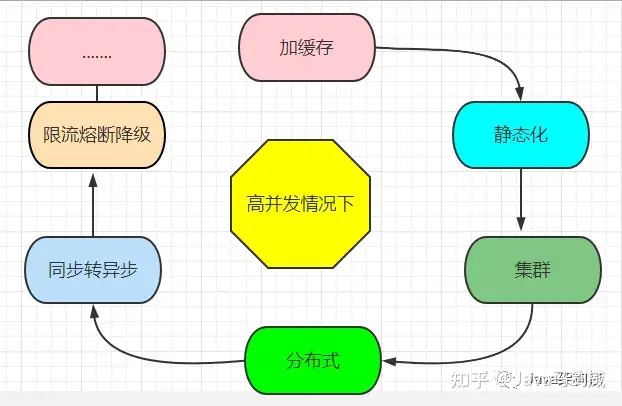
2.1 缓存是高并发的第一策略
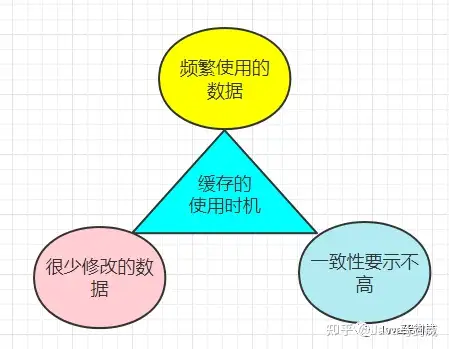
2.2 适合缓存的数据
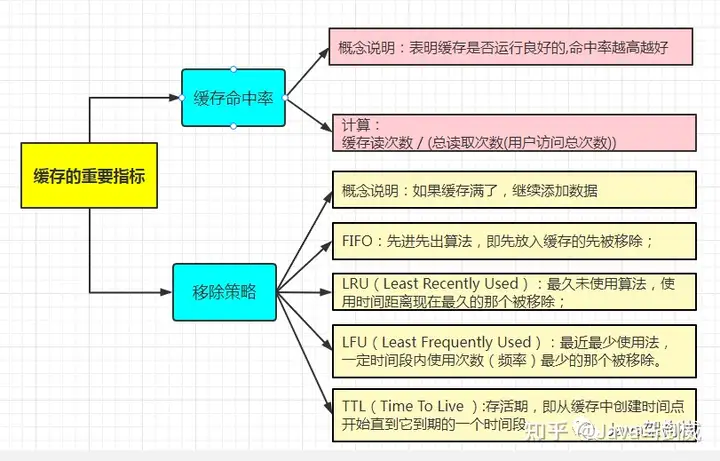
2.3 缓存的重要指标
2.3.1 缓存命中率
从缓存中读取数据的次数:总读取次数 = 比率,命中率越高越好。
命中率 = 从缓存中读取次数 / (总读取次数[从缓存中读取次数 + 从慢速设备上读取的次数]);Miss率 = 没有从缓存中读取的次数 / (总读取次数[从缓存中读取次数 + 从慢速设备上读取的次数])2.3.2 移除策略
参见上图!
三. 基于Redis实现缓存
3.1搭建环境
3.1.1 添加核心依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>
3.1.2 配置Redis
@Configurationpublic class RedisConfig {@Autowiredprivate RedisTemplate redisTemplate;//
序列化设置一下@PostConstructpublic void setRedisTemplate() {redisTemplate.setKeySerializer(new StringRedisSerializer());redisTemplate.setValueSerializer(new JdkSerializationRedisSerializer());}}
3.2 缓存实现
3.2.1 实现流程
3.2.2 核心代码
这里我们以查询省份信息为例进行实现。
@Overridepublic DsAprovinces selectById(Integer id) {String key = String.valueOf(id);DsAprovinces dsAprovinces= null;//1.从redis查dsAprovinces = (DsAprovinces)redisTemplate.opsForValue().get(key);//2.如果不空if(null!= dsAprovinces) {System.out.println("redis中查到了");return dsAprovinces;}//3.查询
数据库dsAprovinces = dsAprovincesMapper.selectById(id);//3.放入缓存if(null!= dsAprovinces) {System.out.println("从数据库中查,放入缓存....");redisTemplate.opsForValue().set(key,dsAprovinces);redisTemplate.expire(key,60, TimeUnit.SECONDS); //60秒有效期}return dsAprovinces;}
3.3 数据库的增删改联动
3.3.1 实现流程
3.3.2 核心代码
//更新:确保机制:实行双删public int update(DsAprovinces dsAprovinces) {redisTemplate.delete(String.valueOf(dsAprovinces.getId()));int i = dsAprovincesMapper.updateById(dsAprovinces);redisTemplate.delete(String.valueOf(dsAprovinces.getId()));return i;}
四. 基于Spring Cache实现缓存
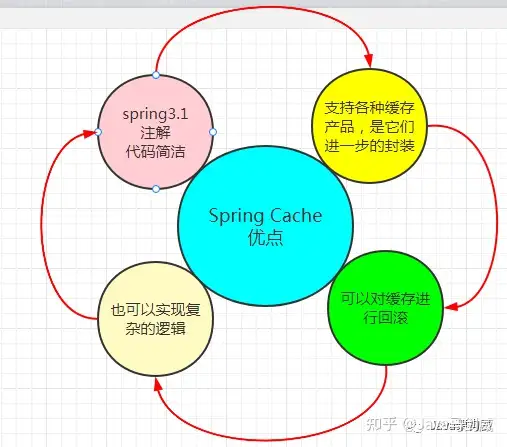
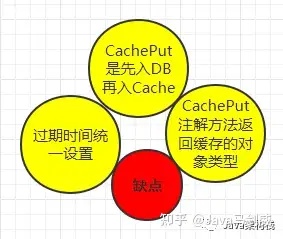
4.1 Spring Cache优点
根据上图可知,Spring Cache具有如下优点:
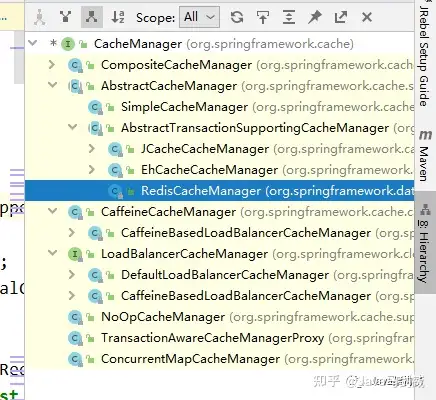
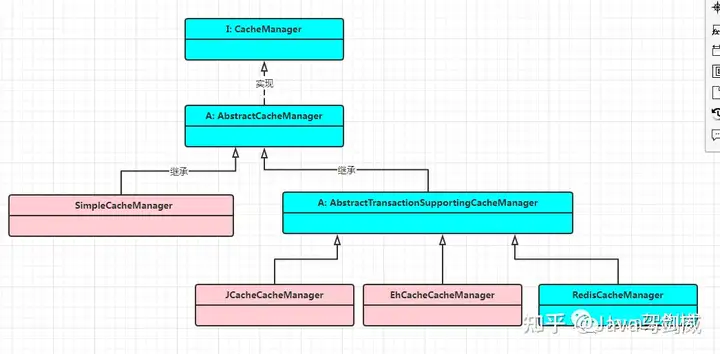
基于注解,代码清爽简洁;支持各种缓存:Spring Cache并非一种具体的缓存技术,而是基于各种缓存产品(如Guava、EhCache、Redis等)进行的一层封装,结合SpringBoot开箱即用的特性用起来会非常方便;可以实现复杂的逻辑;可以对缓存进行回滚4.2 Spring Cache包结构
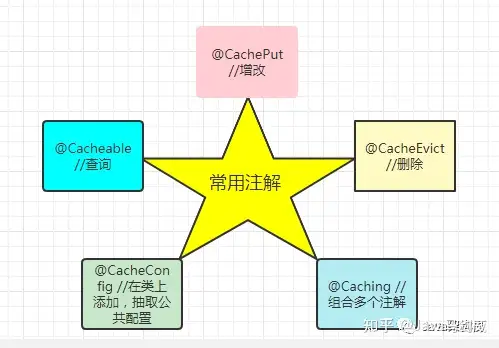
4.3 常用注解
@Cacheable //查询@CachePut //增改@CacheEvict //删除@Caching //组合多个注解@CacheConfig //在类上添加,抽取公共配置4.4 代码实现
4.4.1 配置类
@Configuration@EnableCaching //开启spring缓存public class MyCacheConfig extends CachingConfigurerSupport {//使用redis做为缓存@Beanpublic CacheManager cacheManager(RedisConnectionFactory connectionFactory) {//1.redis缓存管理器RedisCacheManager.RedisCacheManagerBuilder builder = RedisCacheManager.builder(connectionFactory);//2.设置一些参数 //统一设置20s有效期builder.cacheDefaults(RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofSeconds(2000)));builder.transactionAware();RedisCacheManager build = builder.build();return build;}//可以自定义key的生成策略@Overridepublic KeyGenerator keyGenerator() {return new KeyGenerator() {@Overridepublic Object generate(Object target, Method method, Object... objects) {//1.缓冲StringBuilder sb = new StringBuilder();//2.类名sb.append(target.getClass().getSimpleName());//3.方法名sb.append(method.getName());//4.参数值for (Object obj : objects) {sb.append(obj.toString());}return sb.toString();}};}}
4.4.2service层实现类
@Service@Primary@CacheConfig(cacheNames = "provinces") //key键会添加provinces::public class AprovincesServiceImpl2 implements IAprovincesService {@Autowiredprivate DsAprovincesMapper dsAprovincesMapper;@Autowiredprivate RedisTemplate redisTemplate;@Override@Cacheable(key = "#id")//@Cacheablepublic DsAprovinces selectById(Integer id) {//3.查询数据库DsAprovinces dsAprovinces = dsAprovincesMapper.selectById(id);return dsAprovinces;}//更新:确保机制:实行双删@CachePut(key = "#dsAprovinces.id")public DsAprovinces update(DsAprovinces dsAprovinces) {dsAprovincesMapper.updateById(dsAprovinces);return dsAprovinces;}//添加@CachePut(key = "#dsAprovinces.id")public DsAprovinces save(DsAprovinces dsAprovinces) {dsAprovincesMapper.insert(dsAprovinces);return dsAprovinces;}//删除@CacheEvictpublic int delete(Integer id) {int i = dsAprovincesMapper.deleteById(id);return i;}}
4.5 缺点
任何一种技术都不是十全十美的,Spring Cache也不例外,它也有一些缺点,比如:
不能保证数据的一致性:保存和修改数据是,是先修改数据库,然后再进行更新缓存。如果不满意延迟效果,可以不用cache ,用双删。过期进间配置:过期时间统一配置。五.缓存一致性问题
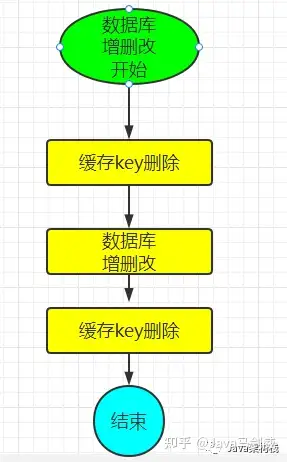
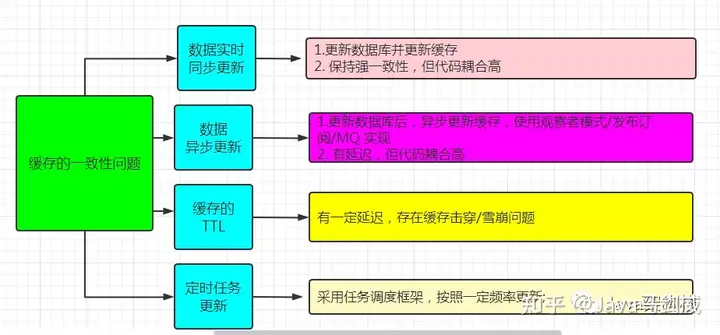
我们在实现Redis缓存时,其实会存在缓存一致性的问题,比如下图所示:
5.1 代码同步更新
强一致性,但代码耦合高。
5.2 代码异步更新
有延迟,借助设计模式或者mq。
5.3 缓存自己的TTL
缓存有一定的延迟,可能造成缓存击穿,或者雪崩问题。
5.4 用定时任务
要把握好更新频率。
6.1 实现流程
解释说明:
缓存击穿和雪崩可以用分布式解决。线程1,代码当前线程线程2,代表和线程1的同类线程。线程3,代表其它线程。6.2 实现代码
6.2.1 核心代码
@Servicepublic class AprovincesServiceImpl3 implements IAprovincesService {@Autowiredprivate DsAprovincesMapper dsAprovincesMapper;@Autowiredprivate RedisTemplate redisTemplate;@Autowiredpublic CacheManager cacheManager;@Overridepublic DsAprovinces selectById(Integer id) {System.out.println("=======================开始");//1.从缓存中取数据Cache provinces1 = cacheManager.getCache("provinces");Cache.ValueWrapper provinces = cacheManager.getCache("provinces").get(id);//2. 如果缓存中有数据,则返回if(null != provinces) {System.out.println("====从缓从中拿数据=======");return (DsAprovinces)provinces.get();}//3.如果缓存中没有,先加把锁doLock(id+"");//DsAprovinces dsAprovinces = null;try {//4.0从第二个线程进来后,查一下provinces = cacheManager.getCache("provinces").get(id);if(null != provinces) {System.out.println("====从缓从中拿数据=======");return (DsAprovinces)provinces.get();}//4.查询数据库dsAprovinces = dsAprovincesMapper.selectById(id);//5.把数据放入缓存if(null != dsAprovinces) {System.out.println("查询数据库,并放入缓存....");cacheManager.getCache("provinces").put(id,dsAprovinces);}} catch (Exception e) {e.printStackTrace();} finally {releaseLock(id+"");}return dsAprovinces;}//=====================================分布式加锁和释放锁封装start=========================//分布式存放锁,这个map是
线程安全的private ConcurrentHashMap<String,Lock> locks = new ConcurrentHashMap<>();//依据主键进行加锁private void doLock(String id) {//1.创建一个
可重入锁ReentrantLock newlock = new ReentrantLock();//2.如 果存在id,则返回旧值,如果不存在, 放入,返回nullLock old = locks.putIfAbsent(id,newlock);//3.如果已存在idif(null != old) {old.lock();}else {newlock.lock();}}//释放 一下private void releaseLock(String id) {//获取到锁ReentrantLock lock = (ReentrantLock)locks.get(id);//判断if(null != lock && lock.isHeldByCurrentThread() ) {lock.unlock();}}//=====================================分布式加锁和释放锁封装end=========================
6.2.2 测试CountDownLatch
CountDownLatch cw = new CountDownLatch(8);@GetMapping("/selectById1/{id}")public DsAprovinces selectById1(@PathVariable Integer id) {for (int i = 0; i < 8; i++) {new Thread(new Runnable() {@Overridepublic void run() {try {cw.await();aprovincesService.selectById(id);} catch (InterruptedException e) {e.printStackTrace();} finally {}}}).start();cw.countDown();}return aprovincesService.selectById(id);}
6.2.3测试结果
七. 小结
至此,就带大家利用Spring Cache实现了分布式缓存,我们在开发时要依据具体的业务逻辑具体地分析解决。其实在项目中并没有固定的格式,只要大家选择适合自己项目场景的方案即可。不知道你现在还有哪些问题呢?可以在评论区给分享你的意见哦。




暂无评论数据