2021-11-4更新,方法已经变了,但是推特所有的数据还是可以正常爬取,不过需要部署Linux,python3环境的服务器会方便很多。
老铁们别光收藏啊!点个赞呗~
最近因为工作需要爬虫了一段时间推特
Twitter网站是用AJAX异步加载的,用request请求到json文件的数据url也是拒绝的
所以只能慢慢模拟浏览器下滑慢慢加载json文件咯(当然我没有用类似于selenium一类的库,效率太低)
ok,现在的功能大概如下:
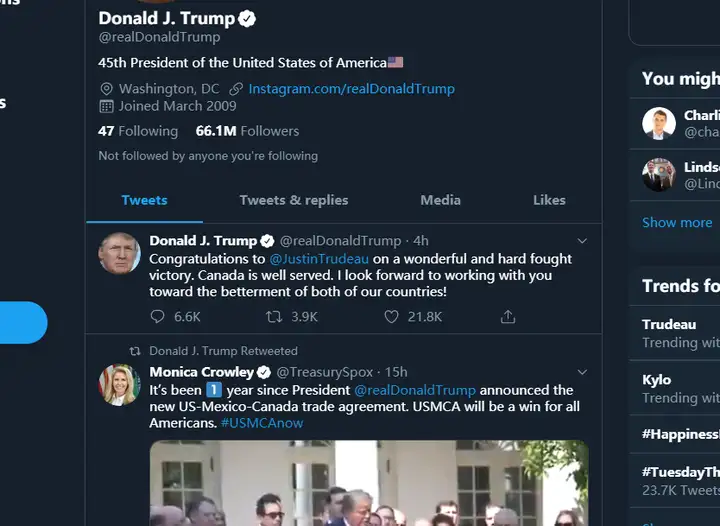
1、用于访问和下载某人的全部推特:如爬取特朗普注册以来发的所有推特信息
2、以及大范围的推特爬取,某个地区,某种语言或包含某个关键字的的推特内容 如:爬取推特在2019-5-20到2019-6-20 出现过 “比特币”字段的所有推特信息
3、爬取某个账户的粉丝,关注者信息以及推特下的评论 ,如:爬取韩寒粉丝的签名,地理位置,昵称,以及韩寒每条推特下的评论
差不多就酱吧
举个例子:
我们需要爬trump的100000条推特,输入以下命令就行了
GetOldTwitter --username "realDonaldTrump" --toptweets --maxtweets 100000
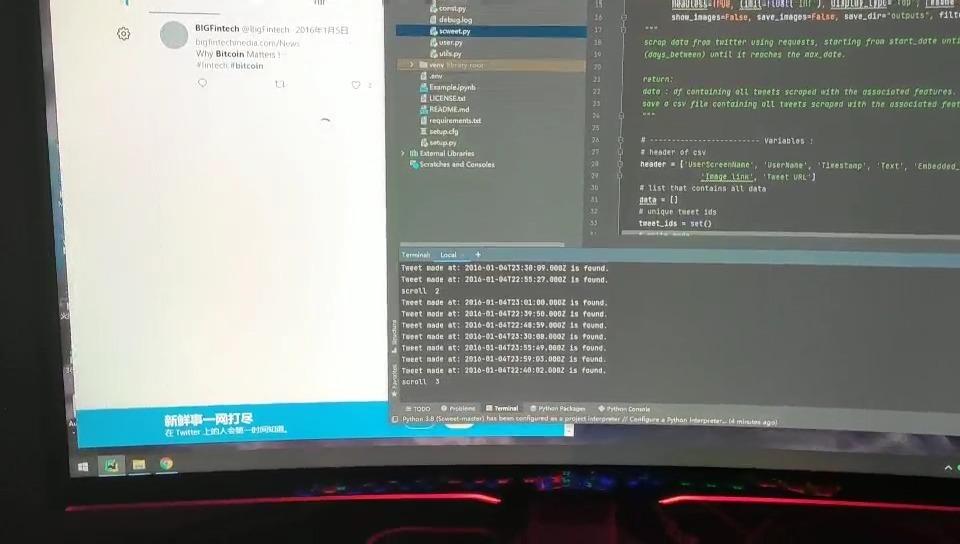
爬虫结果如下(因为用windows系统需要fanqiang,所以直接在linux下使用了)
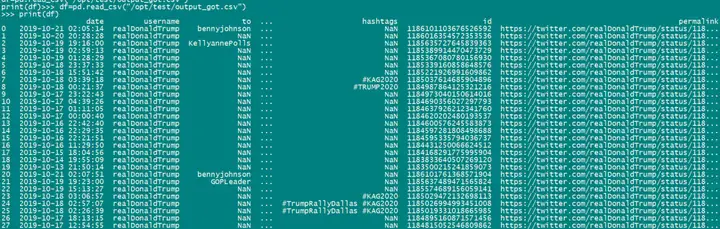
用python代码读一下csv文档(穷苦民众只能买没有图形界面的服务器):
import csvimport pandas as pddf=pd.read_csv("/opt/test/output_got.csv")print(df)
确实是没有问题
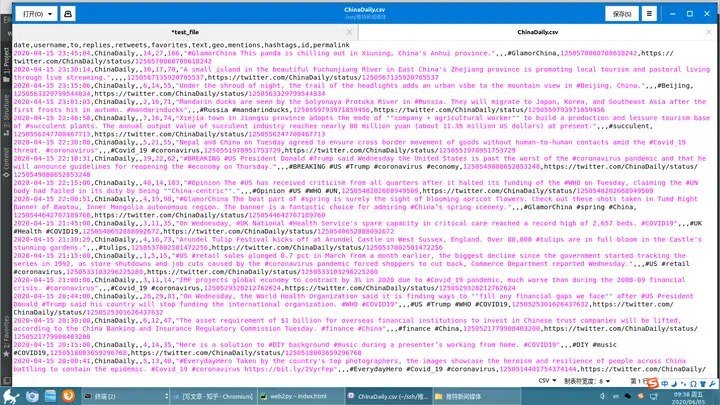
再试试其他媒体,比如Chinadaily
用csv打开试试爬取某人的全部粉丝(韩寒..)
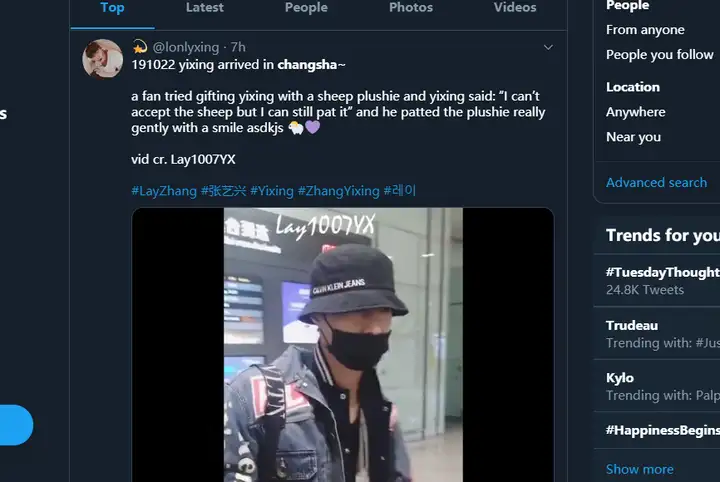
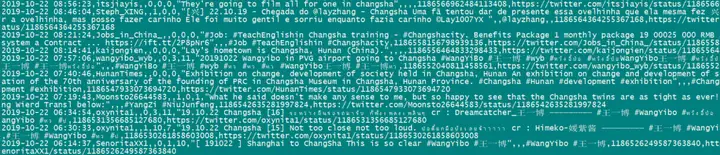
再比如,我们想检索在推特上搜索 “changsha”的新闻
GetOldTwitter -qsearch " changsha " --maxtweets 10
该有的信息都有没什么问题,如果在windows系统下不能使用可以私信我或者应该是被墙住了吧
优秀的程序员我觉得就是要一键和兼容 ,具体怎么使用看看我写的readme就行了
具体github地址如下:
希望各位有需要的老哥可以fork我一下,谢谢!!!!对我蛮重要的,感恩!
当然,情感分析,事件抽取一类的事情我也做不来,只是做了一部分原始数据的来源爬虫,
有时间应该会更新看有没有办法绕过twitter开发者账号比如爬取关注的人,多级关注等
有个老哥私信我好几次了,你先用这个代码爬一下关注者和评论信息吧,json格式的
import sslimport jsonimport urllib.requestfrom bs4 import BeautifulSoupfrom urllib.request import urlopenssl._create_default_https_context = ssl._create_unverified_contextimport tweepy#这个账号自己去申请,不好意思哦consumer_key = lr7GQ6kTaSBkjQVconsumer_secret = oxrXDT8TxsYRqIfk0k7vsX6zHyHSZ7fwZRaccess_token = 3388759955-FOU7cDJApQLDRjIbvICPCJtT5access_token_secret = qEvay5uQUxt0sTlHclSeI1KrblHJR8Xauth = tweepy.OAuthHandler (consumer_key, consumer_secret)auth.set_access_token (access_token, access_token_secret)api = tweepy.API (auth)api = tweepy.API(auth, wait_on_rate_limit=True)results=api.friends(id="markturnery2k") #id就是你要查的user_idprint(results)
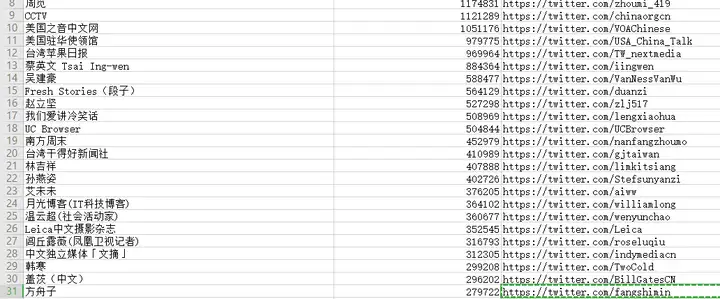
最后,本人还整理了一推特粉丝排名,如中文用户排名,热点事件参与等等..
2021年4月22更新:
之前的方法已经有很多用不了了,现在爬一些数据我个人更多的是用selenium模拟浏览器:
配置代码:
会出现骑不动额问题可能否from io import StringIO, BytesIOimport osimport refrom time import sleepimport randomimport chromedriver_autoinstallerfrom selenium.common.exceptions import NoSuchElementExceptionfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Optionsimport datetimeimport pandas as pdimport platformfrom selenium.webdriver.common.keys import Keys# import pathlibfrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import Byimport constimport urllib# utils文件,配置地址,xpath选择def get_data(card, save_images = False, save_dir = None):"""Extract data from tweet card"""image_links = []try:username = card.find_element_by_xpath(.//span).textexcept:returntry:handle = card.find_element_by_xpath(.//span[contains(text(), "@")]).textexcept:returntry:postdate = card.find_element_by_xpath(.//time).get_attribute(datetime)except:returntry:text = card.find_element_by_xpath(.//div[2]/div[2]/div[1]).textexcept:text = ""try:embedded = card.find_element_by_xpath(.//div[2]/div[2]/div[2]).textexcept:embedded = ""#text = comment + embeddedtry:reply_cnt = card.find_element_by_xpath(.//div[@data-testid="reply"]).textexcept:reply_cnt = 0try:retweet_cnt = card.find_element_by_xpath(.//div[@data-testid="retweet"]).textexcept:retweet_cnt = 0try:like_cnt = card.find_element_by_xpath(.//div[@data-testid="like"]).textexcept:like_cnt = 0try:elements = card.find_elements_by_xpath(.//div[2]/div[2]//img[contains(@src, "https://pbs.twimg.com/")])for element in elements:image_links.append(element.get_attribute(src))except:image_links = []#if save_images == True:# for image_url in image_links:# save_image(image_url, image_url, save_dir)# handle promoted tweetstry:promoted = card.find_element_by_xpath(.//div[2]/div[2]/[last()]//span).text == "Promoted"except:promoted = Falseif promoted:return# get a string of all emojis contained in the tweettry:emoji_tags = card.find_elements_by_xpath(.//img[contains(@src, "emoji")])except:returnemoji_list = []for tag in emoji_tags:try:filename = tag.get_attribute(src)emoji = chr(int(re.search(rsvg\/([a-z0-9]+)\.svg, filename).group(1), base=16))except AttributeError:continueif emoji:emoji_list.append(emoji)emojis = .join(emoji_list)# tweet urltry:element = card.find_element_by_xpath(.//a[contains(@href, "/status/")])tweet_url = element.get_attribute(href)except:returntweet = (username, handle, postdate, text, embedded, emojis, reply_cnt, retweet_cnt, like_cnt, image_links, tweet_url)return tweet#配置driver from io import StringIO, BytesIOimport osimport refrom time import sleepimport randomimport chromedriver_autoinstallerfrom selenium.common.exceptions import NoSuchElementExceptionfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Optionsimport datetimeimport pandas as pdimport platformfrom selenium.webdriver.common.keys import Keys# import pathlibfrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import Byimport constimport urllib# utils文件,配置地址,xpath选择def get_data(card, save_images = False, save_dir = None):"""Extract data from tweet card"""image_links = []try:username = card.find_element_by_xpath(.//span).textexcept:returntry:handle = card.find_element_by_xpath(.//span[contains(text(), "@")]).textexcept:returntry:postdate = card.find_element_by_xpath(.//time).get_attribute(datetime)except:returntry:text = card.find_element_by_xpath(.//div[2]/div[2]/div[1]).textexcept:text = ""try:embedded = card.find_element_by_xpath(.//div[2]/div[2]/div[2]).textexcept:embedded = ""#text = comment + embeddedtry:reply_cnt = card.find_element_by_xpath(.//div[@data-testid="reply"]).textexcept:reply_cnt = 0try:retweet_cnt = card.find_element_by_xpath(.//div[@data-testid="retweet"]).textexcept:retweet_cnt = 0try:like_cnt = card.find_element_by_xpath(.//div[@data-testid="like"]).textexcept:like_cnt = 0try:elements = card.find_elements_by_xpath(.//div[2]/div[2]//img[contains(@src, "https://pbs.twimg.com/")])for element in elements:image_links.append(element.get_attribute(src))except:image_links = []#if save_images == True:# for image_url in image_links:# save_image(image_url, image_url, save_dir)# handle promoted tweetstry:promoted = card.find_element_by_xpath(.//div[2]/div[2]/[last()]//span).text == "Promoted"except:promoted = Falseif promoted:return# get a string of all emojis contained in the tweettry:emoji_tags = card.find_elements_by_xpath(.//img[contains(@src, "emoji")])except:returnemoji_list = []for tag in emoji_tags:try:filename = tag.get_attribute(src)emoji = chr(int(re.search(rsvg\/([a-z0-9]+)\.svg, filename).group(1), base=16))except AttributeError:continueif emoji:emoji_list.append(emoji)emojis = .join(emoji_list)# tweet urltry:element = card.find_element_by_xpath(.//a[contains(@href, "/status/")])tweet_url = element.get_attribute(href)except:returntweet = (username, handle, postdate, text, embedded, emojis, reply_cnt, retweet_cnt, like_cnt, image_links, tweet_url)return tweet#配置driverdef init_driver(headless=True, proxy=None, show_images=False):""" initiate a chromedriver instance """# create instance of web driverchromedriver_path = chromedriver_autoinstaller.install()options = Options()if headless is True:print("Scraping on headless mode.")options.add_argument(--disable-gpu)options.headless = Trueelse:options.headless = Falseoptions.add_argument(log-level=3)if proxy is not None:options.add_argument(--proxy-server=%s % proxy)if show_images == False:prefs = {"profile.managed_default_content_settings.images": 2}options.add_experimental_option("prefs", prefs)driver = webdriver.Chrome(options=options, executable_path=chromedriver_path)driver.set_page_load_timeout(100)return driver#关键字 翻页等def log_search_page(driver, start_date, end_date, lang, display_type, words, to_account, from_account, hashtag, filter_replies, proximity):""" Search for this query between start_date and end_date"""# format the <from_account>, <to_account> and <hash_tags>from_account = "(from%3A" + from_account + ")%20" if from_account is not None else ""to_account = "(to%3A" + to_account + ")%20" if to_account is not None else ""hash_tags = "(%23" + hashtag + ")%20" if hashtag is not None else "end_date = "until%3A" + end_date + "%20"start_date = "since%3A" + start_date + "%20"if display_type == "Latest" or display_type == "latest":display_type = "&f=live"elif display_type == "Image" or display_type == "image":display_type = "&f=image"else:display_type = ""# filter repliesif filter_replies == True:filter_replies = "%20-filter%3Areplies"else :filter_replies = ""# proximityif proximity == True:proximity = "&lf=on" # at the endelse :proximity = ""path = https://twitter.com/search?q=+words+from_account+to_account+hash_tags+end_date+start_date+lang+filter_replies+&src=typed_query+display_type+proximitydriver.get(path)return pathdef get_last_date_from_csv(path):df = pd.read_csv(path)return datetime.datetime.strftime(max(pd.to_datetime(df["Timestamp"])), %Y-%m-%dT%H:%M:%S.000Z)#模拟登录def log_in(driver, timeout=10):username = const.USERNAMEpassword = const.PASSWORDdriver.get(https://www.twitter.com/login)username_xpath = //input[@name="session[username_or_email]"]password_xpath = //input[@name="session[password]"]username_el = WebDriverWait(driver, timeout).until(EC.presence_of_element_located((By.XPATH, username_xpath)))password_el = WebDriverWait(driver, timeout).until(EC.presence_of_element_located((By.XPATH, password_xpath)))username_el.send_keys(username)password_el.send_keys(password)password_el.send_keys(Keys.RETURN)def keep_scroling(driver, data, writer, tweet_ids, scrolling, tweet_parsed, limit, scroll, last_position, save_images = False):""" scrolling function for tweets crawling"""save_images_dir = "/images"if save_images == True:if not os.path.exists(save_images_dir):os.mkdir(save_images_dir)while scrolling and tweet_parsed < limit:sleep(random.uniform(0.5, 1.5))# get the card of tweetspage_cards = driver.find_elements_by_xpath(//div[@data-testid="tweet"])for card in page_cards:tweet = get_data(card, save_images, save_images_dir)if tweet:# check if the tweet is uniquetweet_id = .join(tweet[:-2])if tweet_id not in tweet_ids:tweet_ids.add(tweet_id)data.append(tweet)last_date = str(tweet[2])print("Tweet made at: " + str(last_date) + " is found.")writer.writerow(tweet)tweet_parsed += 1if tweet_parsed >= limit:breakscroll_attempt = 0while tweet_parsed < limit:# check scroll positionscroll += 1print("scroll ", scroll)sleep(random.uniform(0.5, 1.5))driver.execute_script(window.scrollTo(0, document.body.scrollHeight);)curr_position = driver.execute_script("return window.pageYOffset;")if last_position == curr_position:scroll_attempt += 1# end of scroll regionif scroll_attempt >= 2:scrolling = Falsebreakelse:sleep(random.uniform(0.5, 1.5)) # attempt another scrollelse:last_position = curr_positionbreakreturn driver, data, writer, tweet_ids, scrolling, tweet_parsed, scroll, last_positiondef get_users_follow(users, headless, follow=None, verbose=1, wait=2):""" get the following or followers of a list of users """# initiate the driverdriver = init_driver(headless=headless)sleep(wait)# log in (the .env file should contain the username and password)log_in(driver)sleep(wait)# followers and following dict of each userfollows_users = {}for user in users:# log user pageprint("Crawling @" + user + " "+ follow)driver.get(https://twitter.com/ + user)sleep(random.uniform(wait-0.5, wait+0.5))# find the following or followers buttondriver.find_element_by_xpath(//a[contains(@href,"/ + follow + ")]/span[1]/span[1]).click()sleep(random.uniform(wait-0.5, wait+0.5))# if the log in fails, find the new log in button and log in again.scrolling = Truelast_position = driver.execute_script("return window.pageYOffset;")follows_elem = []follow_ids = set()while scrolling:# get the card of following or followerspage_cards = driver.find_elements_by_xpath(//div[contains(@data-testid,"UserCell")])for card in page_cards:# get the following or followers elementelement = card.find_element_by_xpath(.//div[1]/div[1]/div[1]//a[1])follow_elem = element.get_attribute(href)# append to the listfollow_id = str(follow_elem)follow_elem = @ + str(follow_elem).split(/)[-1]if follow_id not in follow_ids:follow_ids.add(follow_id)follows_elem.append(follow_elem)if verbose:print(follow_elem)print("Found " + str(len(follows_elem)) + " " + follow)scroll_attempt = 0while True:sleep(random.uniform(wait-0.5, wait+0.5))driver.execute_script(window.scrollTo(0, document.body.scrollHeight);)sleep(random.uniform(wait-0.5, wait+0.5))curr_position = driver.execute_script("return window.pageYOffset;")if last_position == curr_position:scroll_attempt += 1# end of scroll regionif scroll_attempt >= 3:scrolling = Falsebreak#return follows_elemelse:sleep(random.uniform(wait-0.5, wait+0.5)) # attempt another scrollelse:last_position = curr_positionbreakfollows_users[user] = follows_elemreturn follows_users#link文件def check_exists_by_link_text(text, driver):try:driver.find_element_by_link_text(text)except NoSuchElementException:return Falsereturn Truedef dowload_images(urls, save_dir):for i, url_v in enumerate(urls):for j, url in enumerate(url_v):urllib.request.urlretrieve(url, save_dir + / + str(i+1) + _ + str(j+1) + ".jpg")
执行代码:
import csvimport osimport datetimeimport argparsefrom time import sleepimport randomimport pandas as pdfrom utils import init_driver, get_last_date_from_csv, log_search_page, keep_scroling, dowload_images# class Scweet():def scrap(start_date, max_date, words=None, to_account=None, from_account=None, interval=5, lang=None,headless=True, limit=float("inf"), display_type="Top", resume=False, proxy=None, hashtag=None,show_images=False, save_images=False, save_dir="outputs", filter_replies=False, proximity=False):"""scrap data from twitter using requests, starting from start_date until max_date. The bot make a search between each start_date and end_date(days_between) until it reaches the max_date.return:data : df containing all tweets scraped with the associated features.save a csv file containing all tweets scraped with the associated features."""# ------------------------- Variables :# header of csvheader = [UserScreenName, UserName, Timestamp, Text, Embedded_text, Emojis, Comments, Likes, Retweets,Image link, Tweet URL]# list that contains all datadata = []# unique tweet idstweet_ids = set()# write modewrite_mode = w# start scraping from start_date until <max_date>init_date = start_date # used for saving file# add the <interval> to <start_dateW to get <end_date> for the first refreshend_date = datetime.datetime.strptime(start_date, %Y-%m-%d) + datetime.timedelta(days=interval)# set refresh at 0. we refresh the page for each <interval> of time.refresh = 0# ------------------------- settings :# file pathif words:if type(words) == str :words = words.split("//")path = save_dir + "/" + words[0] + _ + str(init_date).split( )[0] + _ + \str(max_date).split( )[0] + .csvelse :path = save_dir + "/" + words[0] + _ + str(init_date).split( )[0] + _ + \str(max_date).split( )[0] + .csvelif from_account:path = save_dir + "/" + from_account + _ + str(init_date).split( )[0] + _ + str(max_date).split( )[0] + .csvelif to_account:path = save_dir + "/" + to_account + _ + str(init_date).split( )[0] + _ + str(max_date).split( )[0] + .csvelif hashtag:path = save_dir + "/" + hashtag + _ + str(init_date).split( )[0] + _ + str(max_date).split( )[0] + .csv# create the <save_dir>if not os.path.exists(save_dir):os.makedirs(save_dir)# show images during scraping (for saving purpose)if save_images == True:show_images = True# initiate the driverdriver = init_driver(headless, proxy, show_images)# resume scraping from previous workif resume:start_date = str(get_last_date_from_csv(path))[:10]write_mode = a#------------------------- start scraping : keep searching until max_date# open the filewith open(path, write_mode, newline=, encoding=utf-8) as f:writer = csv.writer(f)if write_mode == w:# write the csv headerwriter.writerow(header)# log search page for a specific <interval> of time and keep scrolling unltil scrolling stops or reach the <max_date>while end_date <= datetime.datetime.strptime(max_date, %Y-%m-%d):# number of scrollsscroll = 0# convert <start_date> and <end_date> to strif type(start_date) != str :start_date = datetime.datetime.strftime(start_date, %Y-%m-%d)if type(end_date) != str :end_date = datetime.datetime.strftime(end_date, %Y-%m-%d)# log search page between <start_date> and <end_date>path = log_search_page(driver=driver, words=words, start_date=start_date,end_date=end_date, to_account=to_account,from_account=from_account, hashtag=hashtag, lang=lang,display_type=display_type, filter_replies=filter_replies, proximity=proximity)# number of logged pages (refresh each <interval>)refresh += 1# number of days crossed#days_passed = refresh * interval# last position of the page : the purpose for this is to know if we reached the end of the page or not so# that we refresh for another <start_date> and <end_date>last_position = driver.execute_script("return window.pageYOffset;")# should we keep scrolling ?scrolling = Trueprint("looking for tweets between " + str(start_date) + " and " + str(end_date) + " ...")print(" path : {}".format(path))# number of tweets parsedtweet_parsed = 0# sleepsleep(random.uniform(0.5, 1.5))# start scrolling and get tweetsdriver, data, writer, tweet_ids, scrolling, tweet_parsed, scroll, last_position = \keep_scroling(driver, data, writer, tweet_ids, scrolling, tweet_parsed, limit, scroll, last_position)# keep updating <start date> and <end date> for every searchif type(start_date) == str:start_date = datetime.datetime.strptime(start_date, %Y-%m-%d) + datetime.timedelta(days=interval)else:start_date = start_date + datetime.timedelta(days=interval)if type(start_date) != str:end_date = datetime.datetime.strptime(end_date, %Y-%m-%d) + datetime.timedelta(days=interval)else:end_date = end_date + datetime.timedelta(days=interval)data = pd.DataFrame(data, columns = [UserScreenName, UserName, Timestamp, Text, Embedded_text, Emojis,Comments, Likes, Retweets,Image link, Tweet URL])# save imagesif save_images==True:print("Saving images ...")save_images_dir = "images"if not os.path.exists(save_images_dir):os.makedirs(save_images_dir)dowload_images(data["Image link"], save_images_dir)# close the web driverdriver.close()return dataif __name__ == __main__:parser = argparse.ArgumentParser(description=Scrap tweets.)parser.add_argument(--words, type=str,help=Queries. they should be devided by "//" : Cat//Dog., default=None)parser.add_argument(--from_account, type=str,help=Tweets from this account (axample : @Tesla)., default=None)help=Resume the last scraping. specify the csv file path., default=False)parser.add_argument(--proxy, type=str,help=Proxy server, default=None)args = parser.parse_args()words = args.wordsmax_date = args.max_datestart_date = args.start_dateinterval = args.intervallang = args.langheadless = args.headlesslimit = args.limitdisplay_type = args.display_typefrom_account = args.from_accountto_account = args.to_accounthashtag = args.hashtagresume = args.resumeproxy = args.proxydata = scrap(start_date=start_date, max_date=max_date, words=words, to_account=to_account, from_account=from_account,hashtag=hashtag, interval=interval, lang=lang, headless=headless, limit=limit,display_type=display_type, resume=resume, proxy=proxy, filter_replies=False, proximity=False)







全部评论 2
psv
Google Chrome Android河马本人
Google Chrome Android