最近在整理任务监控工具的时候,有一个想法是,我能不能在自己的程序中获取当前进程的cpu和内存使用状态的一些信息,我最初的想法是直接在c++中调用top或者ps来获取,然后解析top的返回结果来获取监控信息,但是这样有一个问题就是,很慢!就拿popen来说,执行过程分为三个步骤:1、创建一个管道;2、fork一个子进程;3、调用shell。
creates a pipe stream
creates a new process by
fork()
invokes the Linux shell /bin/sh
这个过程对一个高效的系统来说,是有点难以接受的,所以脑子里就蹦出了一个想法,那些监控工具他们是怎么获取这些监控信息,我直接用他们的方式来获取监控信息,那不是就可以了,抱着这个想法,我们开始接下来的学习。
top是如何计算的
我们都知道top是可以计算cpu使用率和内存使用率的,那么top究竟是怎么计算的呢?我们先来看一下调用一次top的系统调用是咋样的。
strace top -b -n 1
我们可以发现基本上都是在读/proc下的文件,在GUN/Linux操作系统中,/proc是一个位于内存中的伪文件系统(in-memory pseudo-file system)。该目录下保存的不是真正的文件和目录,而是一些“运行时”信息,如系统内存、磁盘io、设备挂载信息和硬件配置信息等。proc目录是一个控制中心,用户可以通过更改其中某些文件来改变内核的运行状态。proc目录也是内核提供给我们的查询中心,我们可以通过这些文件查看有关系统硬件及当前正在运行进程的信息。而top的数据源基本上全部都是来自/proc。关于/proc的每个文件的具体信息可以通过z执行 man 5 proc或者官方网站上获取。
通过上面的系统调用,我们知道了top基本上是通过/proc来获取信息的,那么具体的流程是怎么样的,我们只能去扒一扒源码了,源码下载自procps-ng。
进程cpu使用率计算
top最主要的代码在文件 src/top.c中
int main (int argc, char *argv[]) {before(*argv);// +-------------+ wins_stage_1(); // top (sic) slice configs_reads(); // > spread etc, < parse_args(argc, argv); // > onions etc, < signals_set(); // > lean stuff, < whack_terminal(); // > more stuff. < wins_stage_2(); // as bottom slice // +-------------+// 上面的代码主要是在处理一些参数、窗口之间的内容,就不展开介绍了 // 下面的这个for循环就是用来收集和显示信息 for (;;) {struct timespec ts;// 主要的程序逻辑都在frame_make上 frame_make();if (0 < Loops) --Loops; // 循环参数,-n参数指定 if (!Loops) bye_bye(NULL);if (Frames_signal) { Frames_signal = BREAK_off; zap_fieldstab(); continue; }// 后续省略 }return 0;} // end: main
从上面的top的main函数来看,最主要的逻辑都在frame_make上,在frame_make中,会有调用各种
static void frame_make (void) {// 省略部分#ifdef THREADED_TSK sem_post(&Semaphore_tasks_beg);#elsetasks_refresh(NULL); // 刷新本机上具体的进程信息#endif// 省略部分 summary_show(); // 显示summary汇总信息 Max_lines = (SCREEN_ROWS - Msg_row) - 1;// were now on Msg_row so clear out any residual messages ... putp(Cap_clr_eol);if (!Rc.mode_altscr) {// only 1 window to show so, piece o cake w->winlines = w->rc.maxtasks ? w->rc.maxtasks : Max_lines;scrlins = window_show(w, Max_lines);} else {// maybe NO window is visible but assume, pieces o cakes for (i = 0 ; i < GROUPSMAX; i++) {if (CHKw(&Winstk[i], Show_TASKON)) {frame_hlp(i, Max_lines - scrlins);scrlins += window_show(&Winstk[i], Max_lines - scrlins); // 显示具体的任务信息 }if (Max_lines <= scrlins) break;}}} // end: frame_make
在top.c/frame_make函数中,其实最关键的还是task_refresh这个函数的调用,这个函数用于重新读取/proc/pid(pid为进程id)的信息。
static void *tasks_refresh (void *unused) {// 省略部分procps_uptime(&uptime_cur, NULL);et = uptime_cur - uptime_sav;if (et < 0.01) et = 0.005;uptime_sav = uptime_cur;// if in Solaris mode, adjust our scaling for all cpus // et就表示top刷新的一个间隔时间(单位:秒),如果小于0.01或默认为0.005 // Hertz的获取方法为sysconf(_SC_CLK_TCK)) // 用户计算cpu使用率会使用到的, 进程cpu使用率=进程cpu_stic * 100 / cpu赫兹*间隔时间*cpu数量 // 对于不同进程来说只有具体的cpu_stic不一样,所以可以先把其他部分计算好 Frame_etscale = 100.0f / ((float)Hertz * (float)et * (Rc.mode_irixps ? 1 : Cpu_cnt));// 读取进程信息的模式,如果你用-p指定了进程,那么就会只读取你指定的进程 what = Thread_mode ? PIDS_FETCH_THREADS_TOO : PIDS_FETCH_TASKS_ONLY;if (Monpidsidx) { // 读取指定进程 what |= PIDS_SELECT_PID;Pids_reap = procps_pids_select(Pids_ctx, (unsigned *)Monpids, Monpidsidx, what);} else// 全量读取所有进程信息 Pids_reap = procps_pids_reap(Pids_ctx, what);if (!Pids_reap)error_exit(fmtmk(N_fmt(LIB_errorpid_fmt), __LINE__, strerror(errno)));// 下面为赋值相关,省略} // end: tasks_refresh
因为-p指定进程和不指定进程基本上是差不多的,就是有没有筛选的区别,因为我们直接继续看procps_pids_reap的实现,该文件位于 library/pids.c文件中。
PROCPS_EXPORT struct pids_fetch *procps_pids_reap (struct pids_info *info,enum pids_fetch_type which){// 省略部分 // 打开文件 if (!pids_oldproc_open(&info->fetch_PT, info->oldflags))return NULL;// which是用来表示是否读取线程信息,线程信息位于/proc/pid/tasks/目录 info->read_something = which ? readeither : readproc;/* when in a namespace with proc mounted subset=pid, we will be restricted to process information only */info->boot_tics = 0;if (0 >= procps_uptime(&up_secs, NULL))info->boot_tics = up_secs * info->hertz;// 读取信息 rc = pids_stacks_fetch(info);pids_oldproc_close(&info->fetch_PT);// we better have found at least 1 pid return (rc > 0) ? &info->fetch.results : NULL;} // end: procps_pids_reap
上面的读信息的逻辑就是 library/pids.c文件中 pids_stacks_fetch函数中,这个函数倒是并没有什么难的,主要就是读数据,整理数据,然后把结果放到对应的对象里。
static int pids_stacks_fetch (struct pids_info *info){// 上面部分为初始化申请内存相关的内容,省略// iterate stuff -------------------------------------- n_inuse = 0;// 这里的read_something就是在上个函数中被赋值的函数指针 while (info->read_something(info->fetch_PT, &info->fetch_proc)) {if (!(n_inuse < n_alloc)) {n_alloc += STACKS_GROW;if (!(info->fetch.anchor = realloc(info->fetch.anchor, sizeof(void *) * n_alloc))|| (!(ext = pids_stacks_alloc(info, STACKS_GROW))))return -1; // here, errno was set to ENOMEM memcpy(info->fetch.anchor + n_inuse, ext->stacks, sizeof(void *) * STACKS_GROW);}// 整理一下读取到的信息 if (!pids_proc_tally(info, &info->fetch.counts, &info->fetch_proc))return -1; // here, errno was set to ENOMEM // 把最终的结果放到info->fetch.anchor中 if (!pids_assign_results(info, info->fetch.anchor[n_inuse++], &info->fetch_proc))return -1; // here, errno was set to ENOMEM }//省略部分内容} // end: pids_stacks_fetch
对于读进程信息,主要是调用到info->read_something,上面的例子中,我们看到,这个函数有可能会调用readeither 或者 readproc,因为差异并不大,这里我们就是readproc为例,继续来看信息的读取。该函数位于library/readproc.c文件下。
proc_t *readproc(PROCTAB *restrict const PT, proc_t *restrict p) {proc_t *ret;free_acquired(p);for(;;){if (errno == ENOMEM) goto out;// fills in the path, plus p->tid and p->tgid if (!PT->finder(PT,p)) goto out;// go read the process data // 调用函数指针 ret = PT->reader(PT,p);if(ret) return ret;}out:return NULL;}
这个函数倒是没什么内容,因为主要都是调用了PT->reader的内容,跳转过去看,发现都是函数指针,这里因为是纯c写的,没有成员函数,所以就用了很多函数指针,用函数指针一个不好地方就是,阅读起来会有点费劲,因为你还要找到指针是在哪里赋值的才能找到具体的函数。这里找函数的过程就省略了,反正reader调用的是 library/readproc.c文件下的simple_readproc函数。
static proc_t *simple_readproc(PROCTAB *restrict const PT, proc_t *restrict const p) {// 省略部分if (flags & PROC_FILLSTAT) { // read /proc/#/stat if (file2str(path, "stat", &ub) == -1)goto next_proc;rc += stat2proc(ub.buf, p);}if (flags & PROC_FILLIO) { // read /proc/#/io if (file2str(path, "io", &ub) != -1)io2proc(ub.buf, p);}if (flags & PROC_FILLSMAPS) { // read /proc/#/smaps_rollup if (file2str(path, "smaps_rollup", &ub) != -1)smaps2proc(ub.buf, p);}if (flags & PROC_FILLMEM) { // read /proc/#/statm if (file2str(path, "statm", &ub) != -1)statm2proc(ub.buf, p);}// 还有读/proc的各个文件的,太多了,就只贴了上面几个文件}
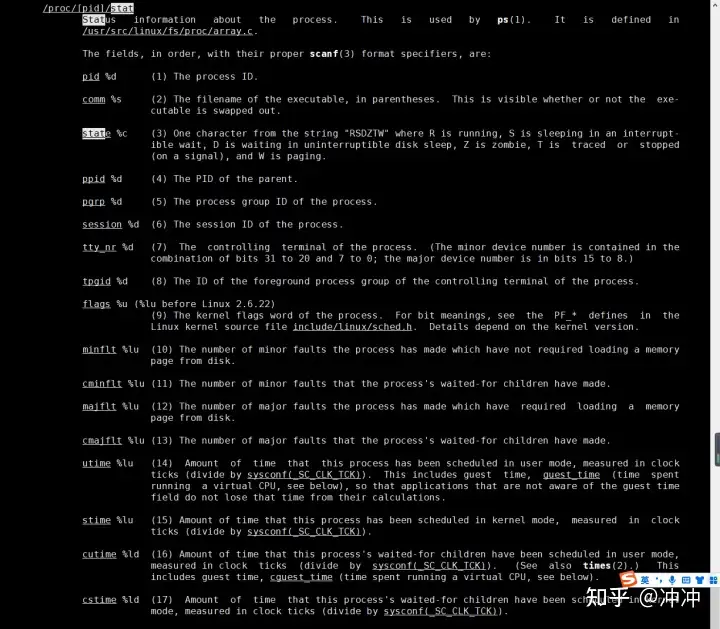
simple_readproc的中就是读具体的/proc/# 下的各个文件,其他不展开介绍了,这里重点展开一下 /proc/#/stat文件,因为我们想要的cpu使用率的源信息就是从这个文件中获取的。我们可以先通过官方文档或者在Linux上执行 man 5 proc看一下这个文件的内容,下面的截图为man 5 proc的部分截图,可以看到,这个文件中有进程状态、cpu时间等等信息。
man 5 proc执行结果的部分截图
可以看看一下真实的结果(self会被解析成当前进程,比如我这里cat一下,那么其实这个信息就是cat的进程信息)。
$cat /proc/self/stat16170 (cat) R 15458 16170 15458 34816 16170 4194304 88 0 0 0 0 0 0 0 20 0 1 0 2940561222 110678016 191 18446744073709551615 4194304 4238828 140726541920448 0 0 0 0 0 0 0 0 0 17 0 0 0 0 0 0 6339656 6341408 32854016 140726541928194 140726541928214 140726541928214 140726541930475 0
library/readproc.c文件下的stat2proc函数就是把上面文件的内容读到proc_t 这个结构体中。
static int stat2proc (const char *S, proc_t *restrict P) {// 省略部分S = strchr(S, (); // 先检查一下有没有左括号,因为第二列的cmd是在括号内的,没有左括号表示不是有效的文件行 if (!S) return 0;S++;tmp = strrchr(S, )); // 字符串从尾部开始找到第一个右括号 if (!tmp || !tmp[1]) return 0;#ifdef FALSE_THREADS if (!IS_THREAD(P)) {#endif if (!P->cmd) {num = tmp - S;memcpy(raw, S, num);raw[num] = \0;escape_str(buf, raw, sizeof(buf));if (!(P->cmd = strdup(buf))) return 1;}#ifdef FALSE_THREADS }#endif // 根据上面找到的位置,跳转到第三列进程state的位置还是用sscanf来读 S = tmp + 2; // skip ") "sscanf(S,"%c " // state "%d %d %d %d %d " // ppid, pgrp, sid, tty_nr, tty_pgrp "%lu %lu %lu %lu %lu " // flags, min_flt, cmin_flt, maj_flt, cmaj_flt "%llu %llu %llu %llu " // utime, stime, cutime, cstime "%d %d " // priority, nice "%d " // num_threads "%lu " // alarm == it_real_value (obsolete, always 0) "%llu " // start_time "%lu " // vsize "%lu " // rss "%lu %lu %lu %lu %lu %lu " // rsslim, start_code, end_code, start_stack, esp, eip "%*s %*s %*s %*s " // pending, blocked, sigign, sigcatch <=== DISCARDED "%lu %*u %*u " // 0 (former wchan), 0, 0 <=== Placeholders only "%d %d " // exit_signal, task_cpu "%d %d " // rt_priority, policy (sched) "%llu %llu %llu", // blkio_ticks, gtime, cgtime &P->state,&P->ppid, &P->pgrp, &P->session, &P->tty, &P->tpgid,&P->flags, &P->min_flt, &P->cmin_flt, &P->maj_flt, &P->cmaj_flt,&P->utime, &P->stime, &P->cutime, &P->cstime,&P->priority, &P->nice,&P->nlwp,&P->alarm,&P->start_time,&P->vsize,&P->rss,&P->rss_rlim, &P->start_code, &P->end_code, &P->start_stack, &P->kstk_esp, &P->kstk_eip,/* P->signal, P->blocked, P->sigignore, P->sigcatch, */ /* cant use */&P->wchan, /* &P->nswap, &P->cnswap, */ /* nswap and cnswap dead for 2.4.xx and up *//* -- Linux 2.0.35 ends here -- */&P->exit_signal, &P->processor, /* 2.2.1 ends with "exit_signal" *//* -- Linux 2.2.8 to 2.5.17 end here -- */&P->rtprio, &P->sched, /* both added to 2.5.18 */&P->blkio_tics, &P->gtime, &P->cgtime);if(!P->nlwp)P->nlwp = 1;return 0;LEAVE(0x160);}
到现在为止,我们就知道了信息的获取方式,但是还是不知道进程的CPU使用率是如何计算的。因此我们再回到src/top.c这个文件中,上面介绍的frame_make函数中,通过window_show函数最终会调用到task_show这个函数中,而我们想要的进程cpu使用率的计算就在这个函数中。
static const char *task_show (const WIN_t *q, int idx) {case EU_CPU: // PIDS_TICS_ALL_DELTA {// 这里获取EU_CPU对应的信息为PIDS_TICS_ALL_DELTA // setDECL(TICS_ALL) { (void)I; R->result.ull_int = P->utime + P->stime; } float u = (float)rSv(EU_CPU, u_int);int n = rSv(EU_THD, s_int);if (Restrict_some) {cp = justify_pad("?", W, Jn);break;}#ifndef TREE_VCPUOFF #ifndef TREE_VWINALL if (q == Curwin) // note: the following is NOT indented #endif if (CHKw(q, Show_FOREST)) u += rSv(eu_TREE_ADD, u_int);u *= Frame_etscale;/* technically, eu_TREE_HID is only valid if Show_FOREST is active but its zeroed out slot will always be present now */if (rSv(eu_TREE_HID, s_ch) != x && u > 100.0 * n) u = 100.0 * n;#else u *= Frame_etscale;/* process cant use more %cpu than number of threads it has ( thanks Jaromir Capik <jcapik@redhat.com> ) */if (u > 100.0 * n) u = 100.0 * n;#endif if (u > Cpu_pmax) u = Cpu_pmax;cp = scale_pcnt(u, W, Jn, 0);}break;} // end: task_show
这里最终的u就是我们计算的cpu使用率,计算cpu的时候用了两个比较关键的rSv(EU_CPU, u_int) 和Frame_etscale,在上面我们在tasks_refresh函数中,已经知道Frame_etscale的计算方式,不清楚的话可以翻上去看下我添加的注释,rSv(EU_CPU, u_int)其实就是cpu_tick_delta,具体获取方式就不展开了,反正就是上面读取之后会放到一个具体的数组里面,感兴趣的话可以再去扒一扒源码,其实就是top刷新间隔的cpu时间增加量,cpu时间的计算方式是/proc/[pid]/stat的第14列(utime)和第15列(stime)相加,转成公式来说的就是
cpu_tick_delta = 当前utime+stime - 上次utime+stime
总结一下,cpu的计算方式就是
cpu使用率 = cpu_tick_delta * 100.0f/((float)Hertz *(float)et *(Rc.mode_irixps ?1: Cpu_cnt));
进程的内存使用率是如何计算的
上面的cpu使用率的数据获取和计算方式我们都知道了,其实内存使用率计算我们也就很容易知道了,和cpu使用率不同的一点是,内存是一个瞬时值,我们是可以拿到进程当前使用的内存大小的,然后除以总内存就是内存使用率了。
这里的当前内存使用的获取,我以为也是用的文件proc/[pid]/stat,因为这个文件的24列(rss)也是进程的当前内存,不过这个rss并不是以正常的内存单位来计数的,因为分配内存的最小单位是page,所以这里的rss就是进程当前page的数量,为了或者真实的内存,我们还需要知道page的大小。但是看了一下代码发现,当前内存的获取是通过文件/proc/[pid]/statm,这个文件的第二列(resident)就直接是当前的内存大小了,并且单位已经换算成了kb。
知道了进程的当前内存,我们还需要知道机器的总内存,机器的总内存在文件/proc/meminfo中,我们cat一下就可以看到,我当前机器的总内存是7822712 kb。
$cat /proc/meminfoMemTotal: 7822712 kBMemFree: 1601628 kBMemAvailable: 6607240 kBBuffers: 286308 kBCached: 4611948 kB# 省略后续内容
有了当前内存和总内存,那么计算内存使用率就比较简单了,top的内存使用率的计算是在 src/top.c文件中的task_show函数中。
static const char *task_show (const WIN_t *q, int idx) {case EU_MEM: // derive from PIDS_MEM_RES if (Restrict_some) {cp = justify_pad("?", W, Jn);break;}// rSv(EU_MEM, ul_int)就表示进程当前的内存大小 // MEM_VAL(mem_TOT)就是当前机器的总内存大小 cp = scale_pcnt((float)rSv(EU_MEM, ul_int) * 100 / MEM_VAL(mem_TOT), W, Jn, 0);break;} // end: task_show
总结
cpu使用率并不是一个瞬时值,我们是无法获取某个时刻具体的cpu使用率的,就好比我们无法通过一张图片来获取其中汽车的速度一样,但是对于汽车的速度,我们还是会有一个瞬时速度来表示,只不过这个瞬时速度的计算方式是通过某个时间段汽车走过的距离来计算的,当这个时间段足够小,那么我们也可以粗略的认为这个速度就是当前时刻的瞬时速度,cpu使用率的计算也是同样的道理,首先系统会把cpu分成很小的时间单位,然后进程消耗了多少个单位cpu会记录在/proc/[pid]/stat中,从进程创建开始就开始累加,如果要计算cpu使用率,比如我们设置的时间间隔是5秒,那么首先会获取到这个在这5秒内增加了多少个cpu的单位,然后再除以这5秒内cpu单位总和,得到的就是进程当前的cpu使用率了。而对于进程的内存使用率而言,其实就是获取当前使用量除以总内存来计算的。



暂无评论数据